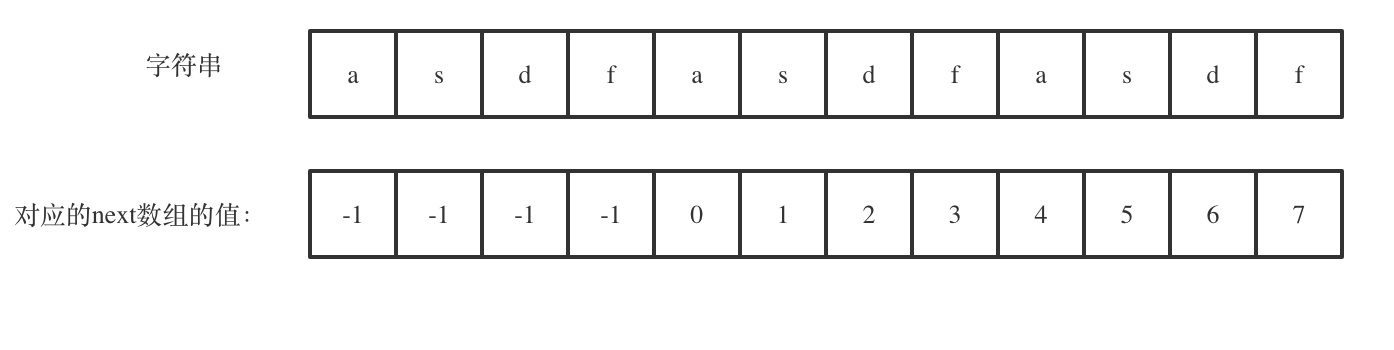
字符串
- 字符串也就相当于一种字符数组,它在java中有许多的库函数比如:
charAt(int index): Returns the character at the specified index in the string.
1
2String str = "Hello";
char character = str.charAt(0); // Returns 'H'
length(): Returns the length of the string.
1
2String str = "Hello";
int length = str.length(); // Returns 5substring(int beginIndex, int endIndex): Returns a substring of the string starting from
beginIndexup to, but not including,endIndex.1
2String str = "Hello";
String subStr = str.substring(0, 3); // Returns "Hel"indexOf(String str): Returns the index of the first occurrence of the specified substring.
1
2String str = "Hello";
int index = str.indexOf("lo"); // Returns 3concat(String str): Concatenates the specified string to the end of the original string.
1
2String str = "Hello";
String newStr = str.concat(" World"); // Returns "Hello World"toLowerCase() / toUpperCase(): Converts the string to lowercase or uppercase.
1
2
3String str = "Hello";
String lowerStr = str.toLowerCase(); // Returns "hello"
String upperStr = str.toUpperCase(); // Returns "HELLO"trim(): Removes leading and trailing whitespaces.
1
2String str = " Hello ";
String trimmedStr = str.trim(); // Returns "Hello"replace(char oldChar, char newChar): Replaces all occurrences of
oldCharwithnewChar.1
2String str = "Hello";
String replacedStr = str.replace('l', 'w'); // Returns "Hewwo"startsWith(String prefix) / endsWith(String suffix): Checks if the string starts or ends with the specified prefix or suffix.
1
2
3String str = "Hello";
boolean startsWith = str.startsWith("He"); // Returns true
boolean endsWith = str.endsWith("lo"); // Returns true声明和转换
1
2
3
4String str = "Hello";
char[] charArray = str.toCharArray();
char[] charArray = {'H', 'e', 'l', 'l', 'o'};
String str = new String(charArray);StringBuilder
1
2
3
4
5StringBuilder sb = new StringBuilder(); // Default initial capacity (16)
StringBuilder sbWithCapacity = new StringBuilder(30); // Initial capacity set to 30
StringBuilder sbWithString = new StringBuilder("Hello"); // Initialize with a string
sb.append(" World"); // Append a string
sb.insert(5, " World"); // Insert a string at index 5
java中的字符串不能进行更改,所以有两种方法一种是转换为char数组,另一种是创建stringbuild对象。
解决字符串的匹配问题最暴力的方法肯定是双层for循环来判断如果没有时间限制,一般可以实现。我们采用这些方法的目的是让我可以在时间和空间上有所提升。从n2到n
反转字符串
需要头尾调换整个字符串,相当于我们实现一个reverse库函数。这里我们可以使用头尾双指针很方便的实现。
1 | public void reverseString(char[] s) { |
反转字符串II
这个题目有自己的反转规则,所以需要根据规则进行反转,所以需要想到的是i += 2 * k,而不是ch.length/2k,因为这样做会更加方便一点,然后还有就是题目的理解了,题目要求只要有k个就翻转k个,没有k个就翻转剩下的,所以最后一步可以直接判断是不是最后所有采用最小值进行替换。
1 | class Solution { |
for循环的执行顺序 for(int i = 0;i < ch.length;i += 2 * k){
}
①int i = 0
②i < ch.length
③i += 2 * k
④循环体
执行过程是①->②->④->③再返回到2
151.翻转字符串里的单词
这个主打一个熟悉很多的解决方法可以使用
使用StringBuilder 移除多余空格,将整个字符串反转,将每个单词反转。其中if 的意义是如果单词不是空格就插入,如果单词是空格就要保证上一次不是空格。
1
2
3
4
5
6
7
8
9
10
11
12int start = 0;
int end = s.length() - 1;
while (s.charAt(start) == ' ') start++;
while (s.charAt(end) == ' ') end--;
StringBuilder sb = new StringBuilder();
while (start <= end) {
char c = s.charAt(start);
if (c != ' ' || sb.charAt(sb.length() - 1) != ' ') {
sb.append(c);
}
start++;
}创建新的字符串数组,对整体数组从后往前遍历,然后设置一个指针记录右侧位置如果是不是空格就添加。两个while循环确定一个单词的左右边界==‘ ’是用来删除空格的
1
2
3
4while(i>=0 && initialArr[i] == ' '){i--;} //跳过空格
//此时i位置是边界或!=空格,先记录当前索引,之后的while用来确定单词的首字母的位置
int right = i;
while(i>=0 && initialArr[i] != ' '){i--;}使用char数组主要体现在移除空格上,操作原理同删除数组中的元素,通过双指针实现。这里是空格的if循环放哪里,更体会到了while遍历整个单词的作用。
1
2
3
4
5
6
7
8
9
10
11
12int slow = 0;
for (int fast = 0; fast < chars.length; fast++) {
//先用 fast 移除所有空格
if (chars[fast] != ' ') {
//在用 slow 加空格。 除第一个单词外,单词末尾要加空格
if (slow != 0)
chars[slow++] = ' ';
//fast 遇到空格或遍历到字符串末尾,就证明遍历完一个单词了
while (fast < chars.length && chars[fast] != ' ')
chars[slow++] = chars[fast++];
}
}
28. 实现 strStr()-KMP
这个大小子串必然是可以使用暴力解决两层for循环,但是另一种很重要的技术就是KMP实现字符串匹配,
KMP理论知识
当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
文章中字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。简单的来说就是匹配串自身存在一定的关联关系,如果它前缀上了,就可以通过最长相等前后缀串切换位置。
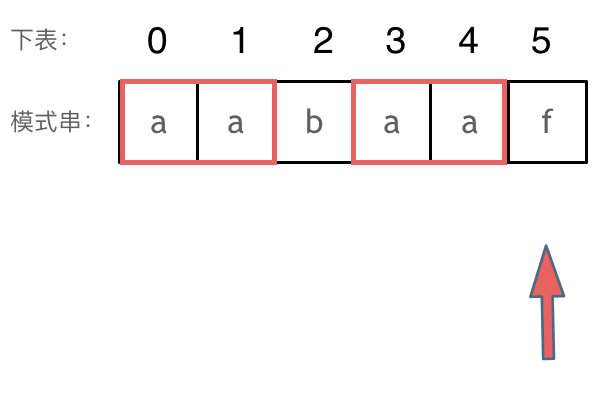

下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面重新匹配就可以了。前缀表体现了不匹配时的之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀和后缀关系,也就是如何移动将前缀匹配串转移到后缀匹配串上。
前缀表如何计算,比如你要计算aa的前缀表就把aa的所有前缀和后缀列出看看最大能匹配上的数目
这里我以aabaa举例
aabaa的前缀子串是a,aa,aab,aaba;
后缀子串是a,aa,baa,abaa;
所以可以很明显的看出最长匹配得前后缀串是aa所以是2,这时候如果f不匹配那么整个串就可以直接从2开始匹配因为前缀aa和后缀aa完全一致。
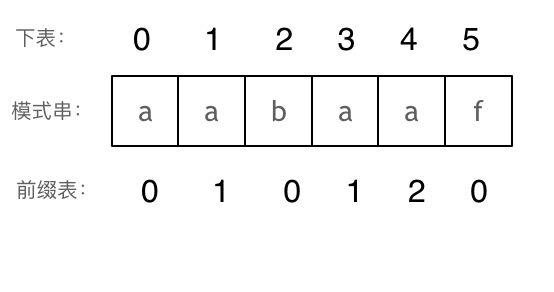
前缀表和Next数组的关系
很多KMP算法的实现都是使用next数组来做回退操作,那么next数组与前缀表有什么关系呢?
next数组就可以是前缀表,但是很多实现都是把前缀表统一减一(右移一位,初始位置为-1)之后作为next数组。减一并右移之后就可以和index对应上了。
以下我们以前缀表统一减一之后的next数组来做演示。
有了next数组,就可以根据next数组来 匹配文本串s,和模式串t了。
注意next数组是新前缀表(旧前缀表统一减一了)。
仅此而已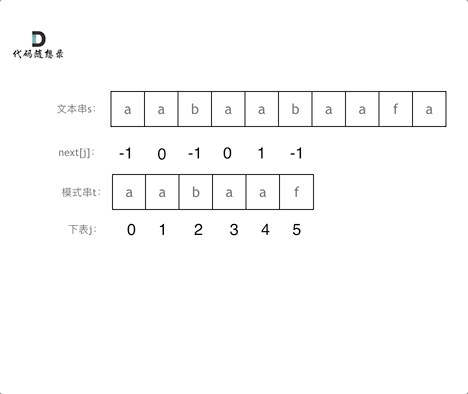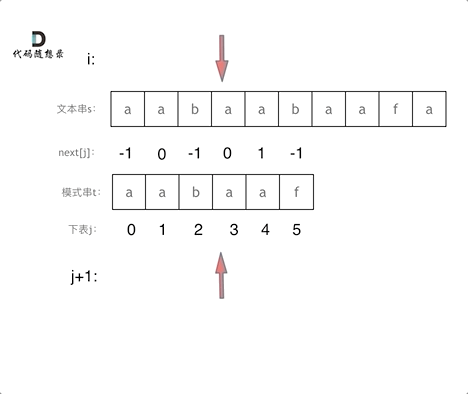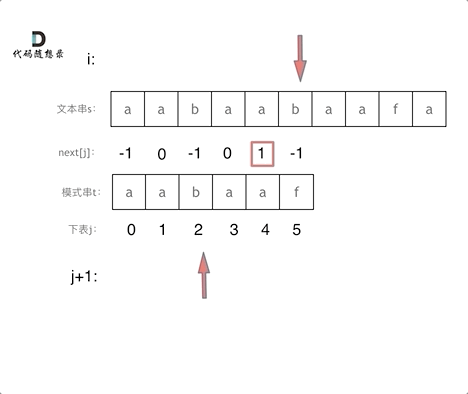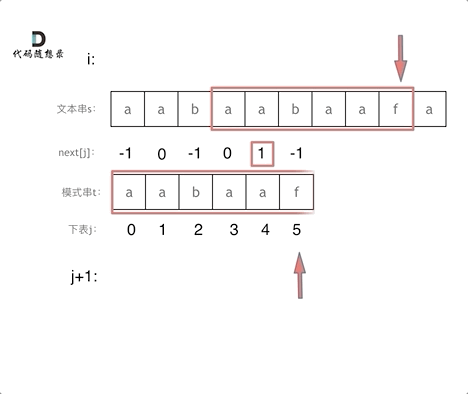
KMP的时间复杂度是O(n+m)暴力的复杂度是O(n × m),所以KMP在字符串匹配中极大地提高了搜索的效率。
KMP具体实现
关键点不是反推出上述模式,而是如何根据上述理论推出代码。
1 | // 方法一 |
1 | class Solution { |
然后大小子串直接做就可以了。
459.重复的子字符串
判断一个串是不是由其子串构成,这时就体现了两个思路
1.将这个串两个连接,然后如果能在其内部找到完整的子串证明其存在船夫的子串。
2.kmp的next 数组记录的是最长公共子前缀那么
证明:
假设字符串s使用多个重复子串构成(这个子串是最小重复单位),重复出现的子字符串长度是x,所以s是由n * x组成。
因为字符串s的最长相同前后缀的长度一定是不包含s本身,所以 最长相同前后缀长度必然是m * x,而且 n - m = 1,(这里如果不懂,看上面的推理)
所以如果 nx % (n - m)x = 0,就可以判定有重复出现的子字符串。
next 数组记录的就是最长相同前后缀这里介绍了什么是前缀,什么是后缀,什么又是最长相同前后缀), 如果 next[len - 1] != -1,则说明字符串有最长相同的前后缀(就是字符串里的前缀子串和后缀子串相同的最长长度)。
最长相等前后缀的长度为:next[len - 1] + 1。(这里的next数组是以统一减一的方式计算的,因此需要+1,
数组长度为:len。
如果len % (len - (next[len - 1] + 1)) == 0 ,则说明数组的长度正好可以被 (数组长度-最长相等前后缀的长度) 整除 ,说明该字符串有重复的子字符串。
数组长度减去最长相同前后缀的长度相当于是第一个周期的长度,也就是一个周期的长度,如果这个周期可以被整除,就说明整个数组就是这个周期的循环。
强烈建议大家把next数组打印出来,看看next数组里的规律,有助于理解KMP算法