动态规划6
583. 两个字符串的删除操作
相比之前现在两个字符串都可以删除,
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
这里和原来的匹配长度的dp定义不同,
- 确定递推公式
- 当word1[i - 1] 与 word2[j - 1]相同的时候
- 当word1[i - 1] 与 word2[j - 1]不相同的时候
当word1[i - 1] 与 word2[j - 1]相同的时候就不删除,那么就取上一个的dp[i][j] = dp[i - 1][j - 1];
当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况:
情况一:删word1[i - 1],最少操作次数为以i-1和j结尾的最少操作次数dp[i - 1][j]再加 1
情况二:删word2[j - 1],最少操作次数为dp[i][j - 1] + 1
情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2
那最后当然是取最小值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
因为 dp[i][j - 1] + 1 = dp[i - 1][j - 1] + 2,所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
这里可能不少录友有点迷糊,从字面上理解 就是 当 同时删word1[i - 1]和word2[j - 1],dp[i][j-1] 本来就不考虑 word2[j - 1]了,那么我在删 word1[i - 1],是不是就达到两个元素都删除的效果,即 dp[i][j-1] + 1。
- dp数组如何初始化
从递推公式中,可以看出来,dp[i][0] 和 dp[0][j]是一定要初始化的。
dp[i][0]:word2为空字符串,以i-1为结尾的字符串word1要删除多少个元素,才能和word2相同呢,很明显dp[i][0] = i。
1 | class Solution { |
方法2:本题和动态规划:1143.最长公共子序列 (opens new window)基本相同,只要求出两个字符串的最长公共子序列长度即可,那么除了最长公共子序列之外的字符都是必须删除的,最后用两个字符串的总长度减去两个最长公共子序列的长度就是删除的最少步数。
1 | class Solution { |
72. 编辑距离
现在不匹配的可以进行的操作变多了,可以进行增删改
1. 确定dp数组(dp table)以及下标的含义
**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。
2. 确定递推公式
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
1 | if (word1[i - 1] == word2[j - 1]) |
也就是如上4种情况。
1 | if (word1[i - 1] == word2[j - 1])` 那么说明不用任何编辑,`dp[i][j]` 就应该是 `dp[i - 1][j - 1]`,即`dp[i][j] = dp[i - 1][j - 1]; |
word1[i - 1] 与 word2[j - 1]相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串word2的最近编辑距离dp[i - 1][j - 1]就是 dp[i][j]了。
在下面的讲解中,如果哪里看不懂,就回想一下dp[i][j]的定义,就明白了。
在整个动规的过程中,最为关键就是正确理解dp[i][j]的定义!
if (word1[i - 1] != word2[j - 1]),此时就需要编辑了,如何编辑呢?
- 操作一:word1删除一个元素,那么就是以下标i - 2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i - 1][j] + 1;
- 操作二:word2删除一个元素,那么就是以下标i - 1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i][j - 1] + 1;
操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增删加元素。
可以回顾一下,if (word1[i - 1] == word2[j - 1])的时候我们的操作 是 dp[i][j] = dp[i - 1][j - 1] 对吧。
那么只需要一次替换的操作,就可以让 word1[i - 1] 和 word2[j - 1] 相同。
所以 dp[i][j] = dp[i - 1][j - 1] + 1;
综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
递归公式代码如下:
1 | if (word1[i - 1] == word2[j - 1]) { |
3. dp数组如何初始化
再回顾一下dp[i][j]的定义:
**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。
那么dp[i][0] 和 dp[0][j] 表示什么呢?
dp[i][0] :以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][0]。
那么dp[i][0]就应该是i,对word1里的元素全部做删除操作,即:dp[i][0] = i;
同理dp[0][j] = j;
所以C++代码如下:
1 | for (int i = 0; i <= word1.size(); i++) dp[i][0] = i; |
4. 确定遍历顺序
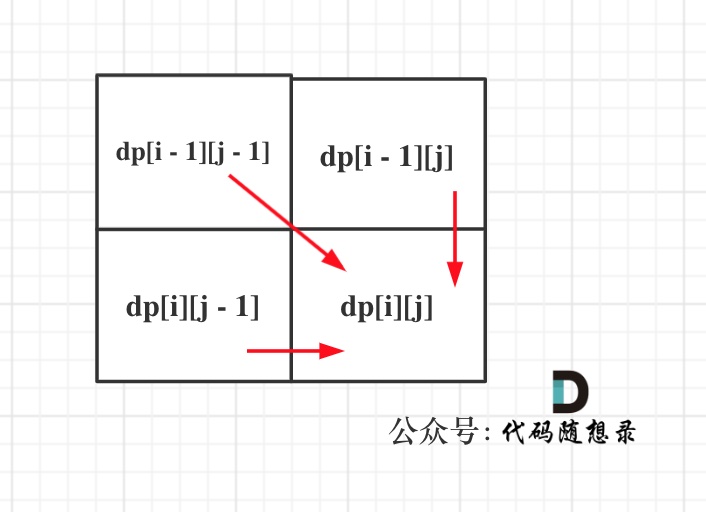
从如下四个递推公式:
dp[i][j] = dp[i - 1][j - 1]dp[i][j] = dp[i - 1][j - 1] + 1dp[i][j] = dp[i][j - 1] + 1dp[i][j] = dp[i - 1][j] + 1
可以看出dp[i][j]是依赖左方,上方和左上方元素的,如图:
1 | class Solution { |
647. 回文子串
- 确定dp数组(dp table)以及下标的含义
如果大家做了很多这种子序列相关的题目,在定义dp数组的时候 很自然就会想题目求什么,我们就如何定义dp数组。
绝大多数题目确实是这样,不过本题如果我们定义,dp[i] 为 下标i结尾的字符串有 dp[i]个回文串的话,我们会发现很难找到递归关系。
dp[i] 和 dp[i-1] ,dp[i + 1] 看上去都没啥关系。
所以我们要看回文串的性质。 如图:
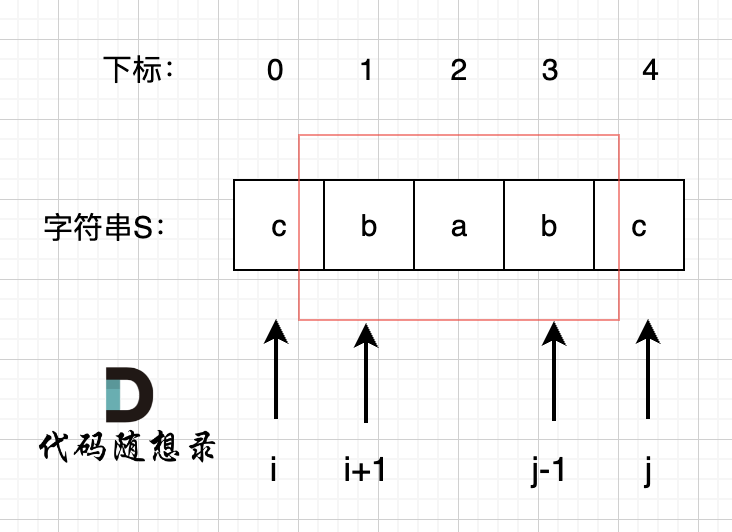
我们在判断字符串S是否是回文,那么如果我们知道 s[1],s[2],s[3] 这个子串是回文的,那么只需要比较 s[0]和s[4]这两个元素是否相同,如果相同的话,这个字符串s 就是回文串。
那么此时我们是不是能找到一种递归关系,也就是判断一个子字符串(字符串的下表范围[i,j])是否回文,依赖于,子字符串(下表范围[i + 1, j - 1])) 是否是回文。
所以为了明确这种递归关系,我们的dp数组是要定义成一位二维dp数组。
布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。
- 确定递推公式
在确定递推公式时,就要分析如下几种情况。
整体上是两种,就是s[i]与s[j]相等,s[i]与s[j]不相等这两种。
当s[i]与s[j]不相等,那没啥好说的了,dp[i][j]一定是false。
当s[i]与s[j]相等时,这就复杂一些了,有如下三种情况
- 情况一:下标i 与 j相同,同一个字符例如a,当然是回文子串
- 情况二:下标i 与 j相差为1,例如aa,也是回文子串
- 情况三:下标:i 与 j相差大于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是不是回文子串就看aba是不是回文就可以了,那么aba的区间就是 i+1 与 j-1区间,这个区间是不是回文就看dp[i + 1][j - 1]是否为true。
以上三种情况分析完了,那么递归公式如下:
1 | if (s[i] == s[j]) { |
result就是统计回文子串的数量。
注意这里我没有列出当s[i]与s[j]不相等的时候,因为在下面dp[i][j]初始化的时候,就初始为false。
- dp数组如何初始化
dp[i][j]可以初始化为true么? 当然不行,怎能刚开始就全都匹配上了。
所以dp[i][j]初始化为false。
- 确定遍历顺序
遍历顺序可有有点讲究了。
首先从递推公式中可以看出,情况三是根据dp[i + 1][j - 1]是否为true,在对dp[i][j]进行赋值true的。
dp[i + 1][j - 1] 在 dp[i][j]的左下角,如图:
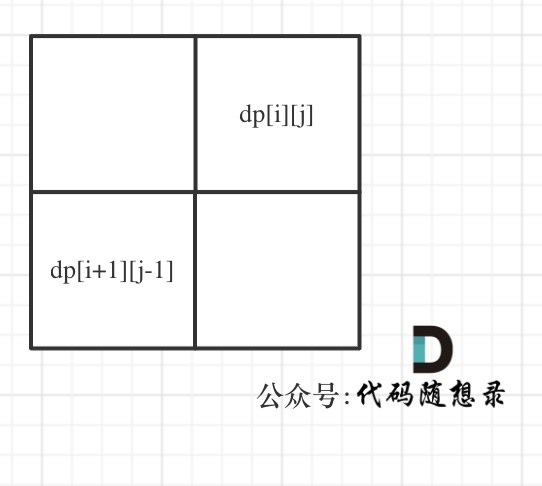
如果这矩阵是从上到下,从左到右遍历,那么会用到没有计算过的dp[i + 1][j - 1],也就是根据不确定是不是回文的区间[i+1,j-1],来判断了[i,j]是不是回文,那结果一定是不对的。
所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的。
有的代码实现是优先遍历列,然后遍历行,其实也是一个道理,都是为了保证dp[i + 1][j - 1]都是经过计算的。
1 | class Solution { |
516.最长回文子序列
1 | class Solution { |