Python数据结构
数据类型
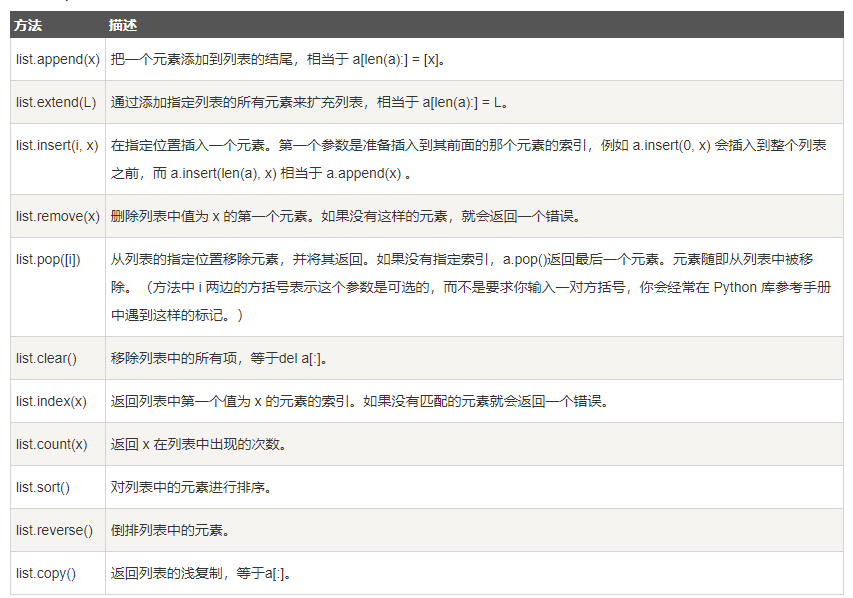
列表(List)
是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,
1 | #定义 |
元组(tuple)
与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。
1 | tuple = ( 'abcd', 786 , 2.23, 'runoob', 70.2 ) |
集合(Set)
是一种无序、可变的数据类型,用于存储唯一的元素。
1 | sites = {'Google', 'Taobao', 'Runoob', 'Facebook', 'Zhihu', 'Baidu'} |
字典(dictionary)
是Python中另一个非常有用的内置数据类型。
列表是有序的对象集合,字典是无序的对象集合
1 | dict = {} |
字符串(string)
是不变对象,对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,
1 | a = 'abc' |
特性
切片
Python提供了切片(Slice)操作符,能大大简化从list取部分元素。
1 | #从索引0开始取,直到索引3为止,但不包括索引3 |
倒数第一个元素的索引是-1
Python中的split()方法是字符串处理中非常常用的一个函数,它用于将字符串拆分为子串,并将这些子串作为列表的元素返回。以下是split()方法的一些常见用法:
- 基本用法:不带任何参数,默认以空格为分隔符拆分字符串。
1 | text = "Hello World" |
- 指定分隔符:通过传递
sep参数来指定一个分隔符。
1 | text = "apple,banana,orange" |
- 限制拆分次数:通过传递
maxsplit参数来限制拆分的次数。
1 | text = "apple,banana,orange,grape" |
在这个例子中,尽管字符串中有三个逗号,但由于maxsplit被设置为2,所以只在前两个逗号处进行了拆分。
- 处理空白字符:如果字符串中有连续的空白字符(空格、制表符、换行符等),
split()方法会默认将它们视为一个分隔符,并忽略它们。
1 | text = "Hello World" |
- 拆分空字符串:如果字符串为空或只包含空白字符,
split()方法会返回一个空列表。
1 | text = "" |
- 结合其他方法使用:
split()方法经常与其他字符串方法(如strip())或列表方法(如join())结合使用,以实现更复杂的字符串处理任务。
例如,去除拆分后每个子串的首尾空白字符:
1 | text = " apple , banana , orange " |
或者使用join()方法将拆分后的子串重新组合成一个字符串:
1 | text = "apple,banana,orange" |
输出
isinstance(a, int)用来判断数据类型
1 | print(str[0:-1]) # 打印字符串第一个到倒数第二个字符(不包含倒数第一个字符) |
括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换。
在括号中的数字用于指向传入对象在 format() 中的位置,如下所示:
1 | print('{0} 和 {1}'.format('Google', 'Runoob')) |
1 | 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125) |
常见占位符
1 | 'Hi, %s, you have $%d.' % ('Michael', 1000000) |
循环
1 | names = ['Michael', 'Bob', 'Tracy'] |
默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
如果要对list实现类似Java那样的下标循环怎么办
1 | for i, value in enumerate(['A', 'B', 'C']): |
同时引用了两个变量
1 | for x, y in [(1, 1), (2, 4), (3, 9)]: |
list+for
1 | [x * x for x in range(1, 11)] |
带有if的判断
1 | [x * x for x in range(1, 11) if x % 2 == 0] |
如果if写在for的后边必须不能带else写在前边必须带else
1 | [x * x if x % 2 == 0 else -1 for x in range(1, 11)] |
Python的for循环本质上就是通过不断调用next()函数实现的
python中函数定义时加上__就是私有函数或者私有变量
函数
python内置函数
1 | abs() |
定义函数
1 | def my_abs(x): |
返回多个值
1 | import math |
其实返回的仍然是一个值但,是一个tuple!但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,Python的函数返回多值其实就是返回一个tuple,但写起来更方便。
默认参数把第二个参数n的默认值设定为2,当我们调用power(5)时,相当于调用power(5, 2),而对于n > 2的其他情况,就必须明确地传入n,比如power(5, 3)。
注意:
一是必选参数在前,默认参数在后,否则Python的解释器会报错(思考一下为什么默认参数不能放在必选参数前面);
二是有多个默认参数时,调用的时候,既可以按顺序提供默认参数,当不按顺序提供部分默认参数时,需要把参数名写上。
三默认参数必须指向不变对象(变量,字符串,元组)!可变对象(集合,字典,列表)
1 | def power(x, n=2): |
可变参数
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数:
1 | def calc(*numbers): |
关键字参数
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。请看示例:
1 | def person(name, age, **kw): |
隐函数
lambda arguments: expression
其中,arguments是函数的参数,expression是函数体,它是一个单一的表达式,其值被返回。
1 | # 定义一个lambda函数,接受两个参数x和y,返回它们的和 |
其他
库导入
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
文件
1 | with open('example.txt', 'r') as file: #读取文件会自动关闭 |
异常
1 | while True: |

类
类的定义
1 | #!/usr/bin/python3 |
注意到__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
在Python中,变量名类似__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用__name__、__score__这样的变量名。
super
在Python中,是否使用super()来调用父类的__init__方法取决于几个因素,包括类的继承结构、你希望在子类中如何定制或扩展父类的行为,以及你对代码可维护性和可读性的考虑。
- 继承结构
- 当你的类是从另一个类继承而来时(单继承),你可能想要调用父类的
__init__方法来设置一些基本的属性或执行一些必要的初始化操作。这时,你可以选择直接使用父类的名字来调用它,或者更普遍地使用super()。 - 在多重继承的场景中,使用
super()尤为重要,因为它确保所有父类的方法被正确调用,而不仅仅是第一个父类。super()提供了一种动态的方式来查找并调用父类的方法,这在多继承结构中特别有用。
- 当你的类是从另一个类继承而来时(单继承),你可能想要调用父类的
- 定制和扩展
- 如果子类需要定制或扩展父类的某些行为,但又不想完全重写父类的
__init__方法,那么可以在子类的__init__方法中使用super()来调用父类的__init__方法,然后添加或修改特定的属性或行为。
- 如果子类需要定制或扩展父类的某些行为,但又不想完全重写父类的
- 可读性和可维护性
- 使用
super()可以使代码更具可读性和可维护性,因为它允许你在不知道具体父类名称的情况下调用父类的方法。这在大型项目或需要频繁修改继承结构的项目中尤其重要。
- 使用
- 多态和动态绑定
- 在某些情况下,使用
super()可以实现多态和动态绑定,这意味着子类可以调用其任意父类中定义的同名方法,并且具体调用哪个父类的方法是在运行时决定的。
- 在某些情况下,使用
- 协作式多重继承
- 当使用多重继承时,一种好的实践是设计父类以便它们能够很好地协同工作。这意味着父类可能预期其子类(或其他子类)将调用它们的方法。在这种情况下,使用
super()可以确保这种协作得到尊重。
- 当使用多重继承时,一种好的实践是设计父类以便它们能够很好地协同工作。这意味着父类可能预期其子类(或其他子类)将调用它们的方法。在这种情况下,使用
- “不是必须”的情况
- 值得注意的是,并不是所有情况下都必须调用父类的
__init__方法。有时,子类可能完全不需要或不想继承父类的任何初始化行为。在这种情况下,子类可以自由地实现自己的__init__方法,而不必调用super()。
- 值得注意的是,并不是所有情况下都必须调用父类的
类的继承
继承有什么好处?最大的好处是子类获得了父类的全部功能。由于Animial实现了run()方法,因此,Dog和Cat作为它的子类,什么事也没干,就自动拥有了run()方法:
1 | class Animal(object): |
继承的第二个好处需要我们对代码做一点改进。你看到了,无论是Dog还是Cat,它们run()的时候,显示的都是Animal is running...,符合逻辑的做法是分别显示Dog is running...和Cat is running...。
当子类和父类都存在相同的run()方法时,我们说,子类的run()覆盖了父类的run(),在代码运行的时候,总是会调用子类的run()。这样,我们就获得了继承的另一个好处:多态。
1 | class Dog(Animal): |
1 | #!/usr/bin/python3 |
多态
的好处就是,当我们需要传入Dog、Cat、Tortoise……时,我们只需要接收Animal类型就可以了,因为Dog、Cat、Tortoise……都是Animal类型,然后,按照Animal类型进行操作即可。由于Animal类型有run()方法,因此,传入的任意类型,只要是Animal类或者子类,就会自动调用实际类型的run()方法,这就是多态的意思:
1 | run_twice(Animal()) |
著名的“开闭”原则:
对扩展开放:允许新增Animal子类;
对修改封闭:不需要修改依赖Animal类型的run_twice()等函数。
如果一个变量指向函数或者类,也可以用type()判断:返回的是Class类型
isinstance()判断类型如果继承关系是:
1 | object -> Animal -> Dog -> Husky |
那么,isinstance()就可以告诉我们,一个对象是否是某种类型。先创建3种类型的对象:
1 | a = Animal() |
当在类里定义的固定的属性属于类属性,不归实例所有调用得使用Student.name
1 | class Student(object): |
python可以动态的绑定实例比如一个类本来没有name属性,但是可以通过绑定的方式来进行绑定。
slots
但是,如果我们想要限制实例的属性怎么办?比如,只允许对Student实例添加name和age属性。
1 | class Student(object): |
鸭子特性是什么?
还记得装饰器(decorator)可以给函数动态加上功能吗?对于类的方法,装饰器一样起作用。Python内置的@property装饰器就是负责把一个方法变成属性调用的:
1 | class Student(object): |
@property的实现比较复杂,我们先考察如何使用。把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值,于是,我们就拥有一个可控的属性操作:
1 | s = Student() |
多重继承
对于需要Runnable功能的动物,就多继承一个Runnable,例如Dog:
1 | class Dog(Mammal, Runnable): |
进程
进程创建
multiprocessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
1 | from multiprocessing import Process |
执行结果如下:
1 | Parent process 928. |
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
进程池
1 | from multiprocessing import Pool |
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
1 | from multiprocessing import Process, Queue |
运行结果如下:
1 | Process to write: 50563 |
线程
创建线程
1 | import time, threading |
进程和线程对比
多进程模式最大的优点就是稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程。(当然主进程挂了所有进程就全挂了,但是Master进程只负责分配任务,挂掉的概率低)著名的Apache最早就是采用多进程模式。
多进程模式的缺点是创建进程的代价大,在Unix/Linux系统下,用fork调用还行,在Windows下创建进程开销巨大。另外,操作系统能同时运行的进程数也是有限的,在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题。
计算密集型 vs. IO密集型
是否采用多任务的第二个考虑是任务的类型。我们可以把任务分为计算密集型和IO密集型。
在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。
TCP编程
TCP服务端:
创建套接字,绑定套接字到本地IP与端口
socket.socket(socket.AF_INET,socket.SOCK_STREAM) , s.bind()
开始监听连接 #s.listen()
进入循环,不断接受客户端的连接请求 #s.accept()
然后接收传来的数据,并发送给对方数据 #s.recv() , s.sendall()
传输完毕后,关闭套接字 #s.close()
TCP客户端:
创建套接字,连接远端地址
socket.socket(socket.AF_INET,socket.SOCK_STREAM) , s.connect()
连接后发送数据和接收数据 # s.sendall(), s.recv()
传输完毕后,关闭套接字 #s.close()
客户端
1 | # 导入socket库: |
创建Socket时,AF_INET指定使用IPv4协议,如果要用更先进的IPv6,就指定为AF_INET6。SOCK_STREAM指定使用面向流的TCP协议,这样,一个Socket对象就创建成功,但是还没有建立连接。连接到新浪服务器的80端口,您的操作系统会从可用的临时(或称为“高位”)端口中选择一个来源端口。这个来源端口在TCP连接的另一端(即服务器)上是可见的,但它通常是由操作系统自动分配的,不需要您在应用程序中指定。
建立TCP连接后,我们就可以向新浪服务器发送请求,要求返回首页的内容:
1 | # 发送请求 |
服务器端
服务器会打开固定端口(比如9999)监听,每来一个客户端连接,就创建该Socket连接。由于服务器会有大量来自客户端的连接,所以,服务器要能够区分一个Socket连接是和哪个客户端绑定的。一个Socket依赖4项:服务器地址、服务器端口、客户端地址、客户端端口来唯一确定一个Socket。
服务器端程序
1 | s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) |
1 | # 监听端口: |
1 | while True: |
每个连接都必须创建新线程(或进程)来处理,否则,单线程在处理连接的过程中,无法接受其他客户端的连接:
客户端测试程序:
1 | s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) |
UDP
TCP是建立可靠连接,并且通信双方都可以以流的形式发送数据。相对TCP,UDP则是面向无连接的协议。
使用UDP协议时,不需要建立连接,只需要知道对方的IP地址和端口号,就可以直接发数据包。但是,能不能到达就不知道了。
虽然用UDP传输数据不可靠,但它的优点是和TCP比,速度快,对于不要求可靠到达的数据,就可以使用UDP协议。
我们来看看如何通过UDP协议传输数据。和TCP类似,使用UDP的通信双方也分为客户端和服务器。服务器首先需要绑定端口:
1 | s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) |
创建Socket时,SOCK_DGRAM指定了这个Socket的类型是UDP。绑定端口和TCP一样,但是不需要调用listen()方法,而是直接接收来自任何客户端的数据:
1 | print('Bind UDP on 9999...') |
recvfrom()方法返回数据和客户端的地址与端口,这样,服务器收到数据后,直接调用sendto()就可以把数据用UDP发给客户端。
注意这里省掉了多线程,因为这个例子很简单。
客户端使用UDP时,首先仍然创建基于UDP的Socket,然后,不需要调用connect(),直接通过sendto()给服务器发数据:
1 | s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) |
从服务器接收数据仍然调用recv()方法。仍然用两个命令行分别启动服务器和客户端