推荐系统-时间上下文需求
物品的推荐要注意和上下文,比如用户肯定不会在冬天挑一件短袖,
当用户伤心的时候也不会听喜庆的歌。
时间信息对用户兴趣的影响表现在如下几个方面:
- 用户兴趣是变化的
- 物品也是有生命周期的
- 季节效应
推荐算法的实时性
前边说了用户的兴趣是在不断地变化的,所以推荐系统要做到实时性的推荐。
实现推荐系统的实时性除了对用户行为的存取有实时性要求,还要求推荐算法本身具有实时性,而推荐算法本身的实时性意味着:
- 实时推荐系统不能每天都给所有用户离线计算推荐结果,然后在线展示昨天计算出来的结果。所以,要求在每个用户访问推荐系统时,都根据用户这个时间点前的行为实时计算推荐列表
- 推荐算法需要平衡考虑用户的近期行为和长期行为,即要让推荐列表反应出用户近期行为所体现的兴趣变化,又不能让推荐列表完全受用户近期行为的影响,要保证推荐列表对用户兴趣预测的延续性。
时间上下文推荐算法
最近最热门算法
给定时间T,物品i最近的流行度 ${n_i(T)}$可以定义为 a代表时间衰减
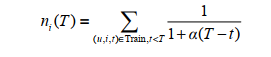
时间上下文相关的ItemCF算法
基于物品( item-based)的个性化推荐算法 主要有两个核心部分
- 利用用户行为离线计算物品之间的相似度;
- 根据用户的历史行为和物品相似度矩阵,给用户做在线个性化推荐。
这正对应着两种时间效应
用户在相隔很短的时间内喜欢的物品具有更高相似度。
用户近期行为相比用户很久之前的行为,更能体现用户现在的兴趣。
经典的相似度计算,上边是是喜欢物品i的用户也喜欢物品j的交集
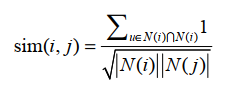
用户u对物品i的兴趣p(u,i)通过如下公式计算:
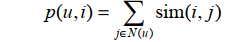
为了体现时间效应
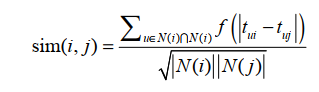
引入一个衰减项f其中 ${t_{ui}}$ 是用户u对物品i产生行为的时间。 f函数的含义是,用户对物品i和物品j产生行为的时间越远,则 f越小。我们可以找到很多数学衰减函数,本节使用如下衰减函数
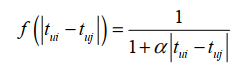
然后用户对物品的兴趣也应该收到时间的影响,用户现在的行为应该和用户最近的行为关系更大 所以修正的用户对于物品i的兴趣如下公式
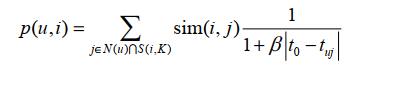
时间上下文的UserItem
经典的用户相关性
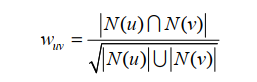
用户对物品的兴趣, 其中, S(u,K)包含了和用户u兴趣最接近的K个用户。如果用户v对物品i产生过行为,那么r=1 ,否则r=0。
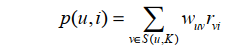
考虑时间信息用户相关性变为
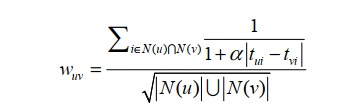
考虑和用户u兴趣相似用户的最近兴趣,我们可以设计如下公式
距离用户v喜欢的这个物品目前越远那么权重就越小
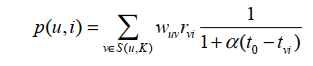
离线实验
对比了如下方法
本节的离线实验将同时对比如下算法,将它们的召回率和准确率曲线画在一张图上。
- Pop 给用户推荐当天最热门的物品。
- TItemCF 融合时间信息的ItemCF算法。
- TUserCF 融合时间信息的UserCF算法。
- ItemCF 不考虑时间信息的ItemCF算法。
- UserCF 不考虑时间信息的UserCF算法。
- SGM 时间段图模型。
- USGM 物品时间节点权重为0的时间段图模型。
- ISGM 用户时间节点权重为0的时间段图模型。
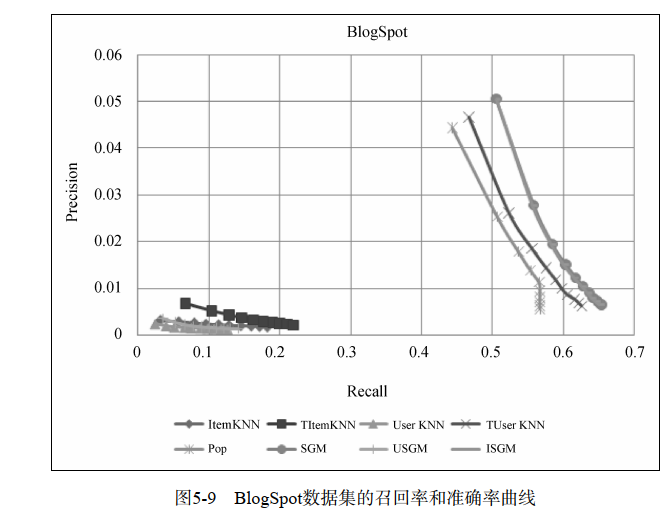
在第一类数据集中,有4个算法( SGM、 ISGM、 TUserCF、 Pop)明显好于另外4个算法 。
地点上下文信息
考虑位置信息主要分为三种
它使用的数据集有3种不同的形式。
- ( 用户, 用户位置, 物品, 评分),每一条记录代表了某一个地点的用户对物品的评分。它们使用的是MovieLens数据集。该数据集给出了用户的邮编,从而可以知道用户的大致地址。
- ( 用户, 物品, 物品位置, 评分),每一条记录代表了用户对某个地方的物品的评分。 LARS使用了FourSquare的数据集,该数据集包含用户对不同地方的餐馆、景点、商店的评分。
- ( 用户, 用户位置, 物品, 物品位置, 评分),每一条记录代表了某个位置的用户对某个位置的物品的评分。
对于第一种数据集, LARS的基本思想是将数据集根据用户的位置划分成很多子集。因为位置信息是一个树状结构,比如国家、省、市、县的结构。因此,数据集也会划分成一个树状结构。然后,给定每一个用户的位置,我们可以将他分配到某一个叶子节点中,而该叶子节点包含了所有和他同一个位置的用户的行为数据集。然后, LARS就利用这个叶子节点上的用户行为数据,通过ItemCF
给用户进行推荐。
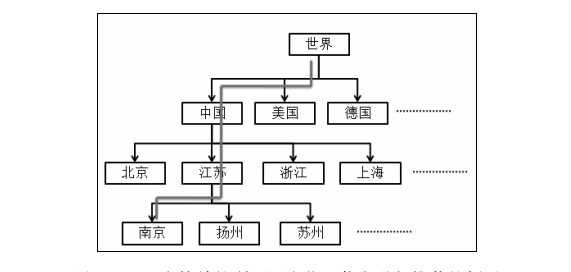
不过这样做的缺点是,每个叶子节点上的用户数量可能很少,因此他们的行为数据可能过于稀疏,从而无法训练出一个好的推荐算法。为此,我们可以从根节点出发,在到叶子节点的过程中,利用每个中间节点上的数据训练出一个推荐模型,然后给用户生成推荐列表。而最终的推荐结果是这一系列推荐列表的加权。文章的作者将这种算法成为金字塔模型,而金字塔的深度影响了推荐系统的性能,因而深度是这个算法的一个重要指标。下文用LARS-U代表该算法。
举一个简单的例子,如图5-16所示,假设有一个来自中国江苏南京的用户。我们会首先根据所有用户的行为利用某种推荐算法(假设是ItemCF)给他生成推荐列表,然后利用中国用户的行为给他生成第二个推荐列表,以此类推,我们用中国江苏的用户行为给该用户生成第三个推荐列表,并利用中国江苏南京的用户行为给该用户生成第四个推荐列表。然后,我们按照一定的权重将这4个推荐列表线性相加,从而得到给该用户的最终推荐列表。
对于第二种数据集,每条用户行为表示为四元组(用户、物品、物品位置、评分),表示了用户对某个位置的物品给了某种评分。对于这种数据集, LARS会首先忽略物品的位置信息,利用ItemCF算法计算用户u对物品i的兴趣P(u,i),但最终物品i在用户u的推荐列表中的权重定义为:
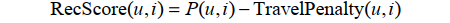
在该公式中, TravelPenalty(u,i)表示了物品i的位置对用户u的代价。计算TravelPenalty(u,i)的基本思想是对于物品i与用户u之前评分的所有物品的位置计算距离的平均值(或者最小值)。关于如何度量地图上两点的距离,最简单的是基于欧式距离①。当然,欧式距离有明显的缺点,因为人们是不可能沿着地图上的直线距离从一点走到另一点的。比较好的度量方 式是利用交通网络数据,将人们实际需要走的最短距离作为距离度量。