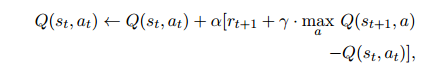背景
目前的研究主要集中在变分量子算法,之前的研究提出了利用变分量子算法来增强有监督、无监督和强化学习(RL)算法的建议。在这项工作中,我们采用一种基于深度q -学习算法的**参数化量子电路(PQC)**训练方法,该方法可用于解决离散和连续状态空间的RL任务。实验结果表明体系结构选择和超参数比模型中使用的参数数量对智能体的成功贡献更大。
经典强化学习
Q-learning关注的不是状态值函数,而是对密切相关的动作值函数Q(s, a)。
然后通过充分探索状态和动作空间。这为智能体提供了足够的信息来区分给定特定状态下的好行为和坏行为。来学习Q函数学习方法