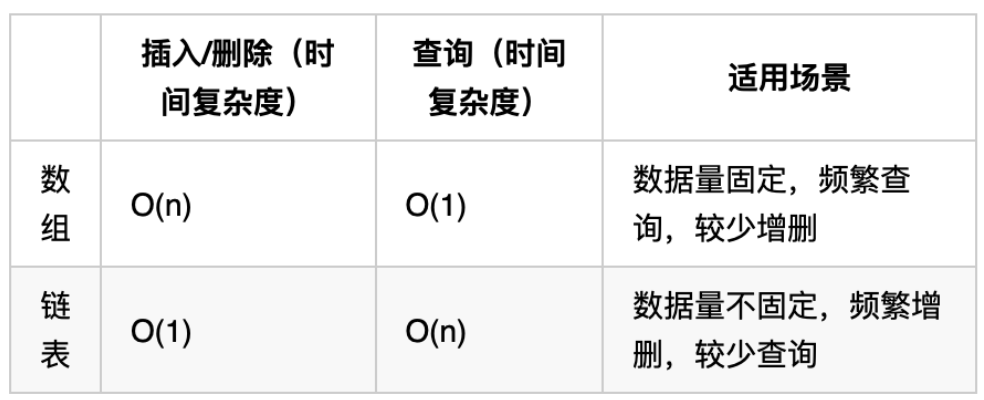
强化学习(reinforcement learning,RL)讨论的问题是智能体(agent)怎么在复杂、不确定的环境(environment)里面去最大化它能获得的奖励。
强化学习概念
智能体
做出动作,并影响于环境
环境
返回作用后的状态,和上一步的奖励
奖励
是由环境给可显示智能体在某一步采取某个策略的表现如何?
强化学习(reinforcement learning,RL)讨论的问题是智能体(agent)怎么在复杂、不确定的环境(environment)里面去最大化它能获得的奖励。
做出动作,并影响于环境
返回作用后的状态,和上一步的奖励
是由环境给可显示智能体在某一步采取某个策略的表现如何?
是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,
1 | #定义 |
栈与队列是常用的数据结构,其中栈提供先进后出,队列提供先进先出,这样的数据结构可以解决一些需要顺序解决的问题。在java中实现底层是不一样的原因是栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的(也就是说我们可以控制使用哪种容器来实现栈的功能)。
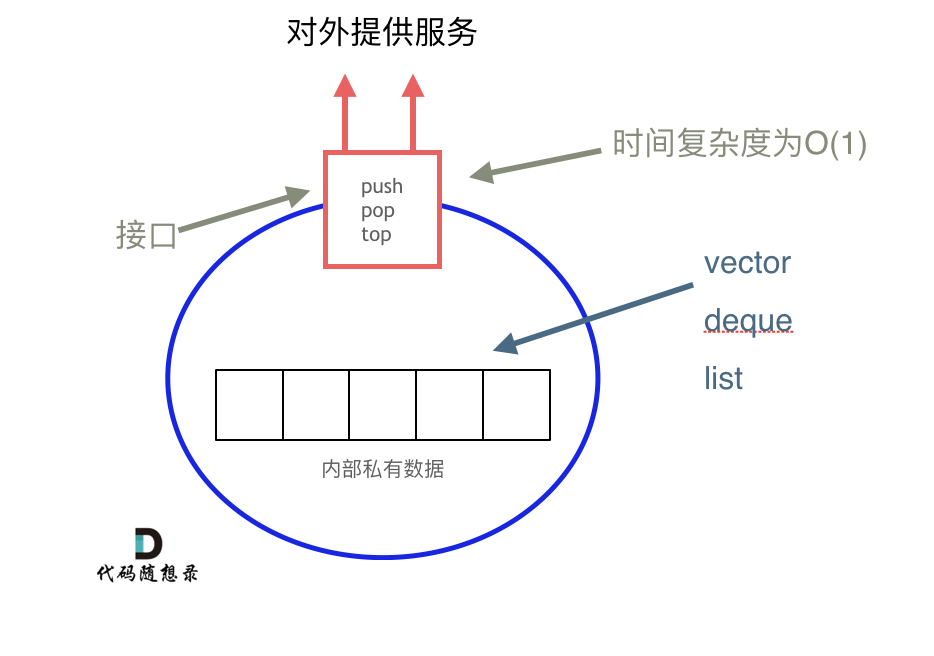
在Java中,队列和栈是两种常见的数据结构,它们分别用于不同的场景,而它们的实现通常基于以下几种容器:
charAt(int index): Returns the character at the specified index in the string.
1 | String str = "Hello"; |
一般哈希表都是用来快速判断一个元素是否出现集合里。但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。Hash法的优势就是牺牲了空间去换了时间,在工业场景中也很适用。
哈希函数打比方:就是将学生姓名映射为哈希表上的索引,通过特定编码方式生成hashCode。如果hashCode超过哈希表大小(tableSize),会进行取模操作以确保映射在表内。但如果学生数量大于表大小,可能导致多个学生映射到同一索引位置。
相比之前现在两个字符串都可以删除,
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
这里和原来的匹配长度的dp定义不同,